

Data Engineering Best Practices
In the dynamic realm of data utilization, data engineering stands as the cornerstone for transforming raw information into strategic assets.
Contemporary data integration tools and advanced data engineering techniques have the potential to streamline and accelerate the tasks of cleansing, transforming, and consolidating data from diverse sources, preparing it for analytics efficiently. Cloud-based data architectures offer the agility to onboard new data sources within minutes and scale storage and computing resources rapidly. This adaptability enhances the potential for extracting greater value from your data. However, for many organizations, the swift accumulation of data has led to the emergence of disorganized, isolated data silos, leaving them perplexed about how to derive meaningful insights.
Drawing upon our proficiency in data engineering and our extensive knowledge of the modern data stack We’ve created reusable frameworks for ELT and ETL paradigms which allow you to quickly ingest data to your data sinks with consistent naming conventions, auditable processes, and easily understood lineage for the ingestion pipeline. We ensure the efficiency of your data pipeline, seamlessly orchestrating data from all sources to a state where transformative analysis becomes achievable.
At DATA LEAGUE, we take a collaborative approach to data engineering consulting. We strongly believe that the best solutions are achieved through close collaboration with our clients. We work closely with them to understand their unique needs and challenges. Our team of expert data engineers has extensive experience in working with a wide range of industries and technologies. We use this knowledge to design custom solutions that are tailored to our clients' specific requirements.
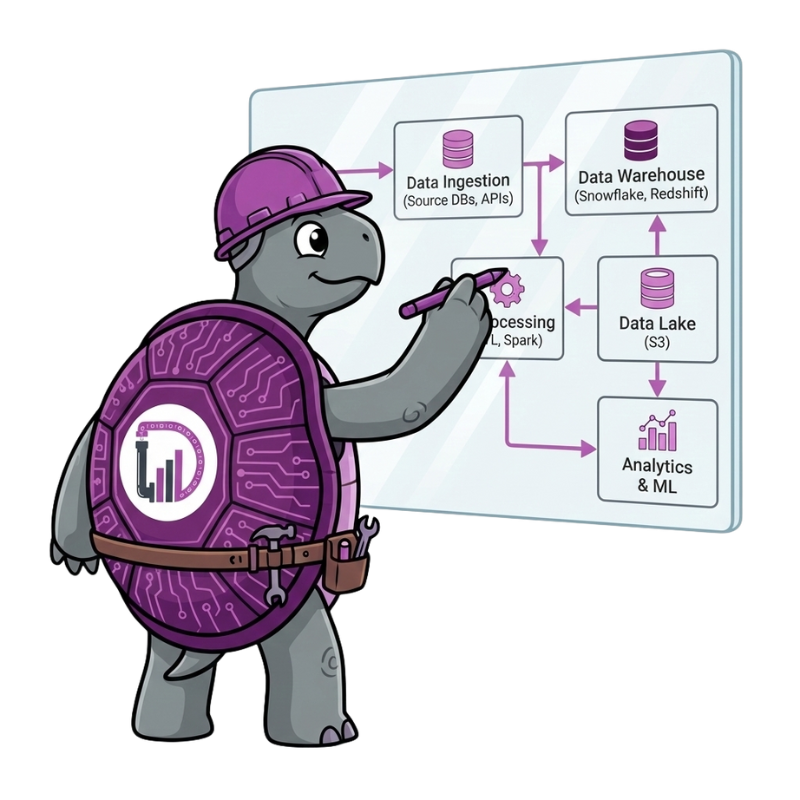
We can help you identify the data that is most important to your business and develop a plan to collect, store, and analyse it effectively.
We can help you choose the right technology stack for your business.
We can help you integrate your data from multiple sources and transform it with your business rules into a format that is trustable and suitable for analysis.
We can help you ensure that your data is accurate, consistent, and reliable by establishing data quality standards and implementing processes to monitor.
We provide ongoing support and maintenance services to ensure that your data engineering systems are running smoothly and help you troubleshoot issues, optimize performance, and implement new features as needed.
We partnered with leading data products in the industry to provide top notch service to our clients.

Our Data Engineering experts can help you no matter wherever you are on your transformation journey.
What our clients say about us

We engaged DATA LEAGUE across two significant projects, and the experience has been outstanding from start to finish. On our first engagement with Indigo, DATA LEAGUE tackled the integration of our HR systems, project that required moving away from manual data updates to a fully API-driven approach, underpinned by a robust metadata framework. This has significantly reduced operational overhead and improved data reliability across our HR Power BI.
For our iLA platform, DATA LEAGUE and the team delivered a comprehensive data warehouse setup with a full DataOps implementation. The result was a markedly more secure environment and a streamlined deployment pipeline that has improved how we manage and release data infrastructure. The consultants brought deep technical expertise, clear communication, and a pragmatic approach to both engagements. We would not hesitate to recommend DATA LEAGUE to any organisation looking for a trusted data engineering partner.
Frequently Asked Questions
Data Warehouse, Data Lake, and Data Lakehouse are all concepts in the realm of data storage and management, each serving distinct purposes. They represent the evolution of data storage philosophy.
Data Warehouse: A Data Warehouse is a traditional standard, a centralized repository that consolidates data from various sources, transforming and organizing it for efficient querying and analysis. It stores structured data (rows and columns) that has been processed and cleaned. It is like a filing cabinet, everything must be filed correctly before it can be stored. It is optimised for fast, reliable reporting (Business Intelligence) but is expensive and inflexible with new data types.
Data Lake: A response to the Big Data explosion. It is a vast, scalable storage repository that houses both structured and unstructured data. It stores raw data in its native format (documents, images, logs, JSON). It is like a massive reservoir, where you can dump anything in without processing it first. It is cheap and scalable but can become a "Data Swamp" if not managed, making retrieval difficult. It acts as a catch-all for diverse data types and allows for data exploration, enabling data scientists and analysts to delve into the data without prior structuring.
Data Lakehouse: The modern hybrid. It combines the low-cost, flexible storage of a Data Lake with the structure, management, and performance features of a Data Warehouse. It allows for ACID transactions (reliability) on top of raw data, supporting both BI (reporting) and AI (machine learning) workloads on a single platform. The Lakehouse architecture strives to make data processing and analytics more streamlined and accessible, allowing for near-real-time data insights without compromising on data reliability.
Data engineering and data modeling are two distinct but interconnected aspects of the data management process. They serve different purposes and focus on different stages of the data lifecycle. Let's explore the differences between data engineering and data modeling:
| Aspect | Data Engineering | Data Modeling |
|---|---|---|
| Purpose | Data engineering is the process of designing, building, and maintaining the infrastructure and systems that facilitate the collection, storage, and processing of data. | Data modeling is the process of defining the structure, relationships, and constraints of data to represent the business concepts accurately. |
| Focus | Data engineering focuses on the technical aspects of data, such as data pipelines, data warehouses, data lakes, data integration, and data transformation. "How do we move this data from A to B efficiently and reliably?" | Data modeling focuses on the logical representation of data ("How does this data relate to the real world?"), abstracting the complexities of the underlying technical implementation. The modeler draws the blueprint; the engineer builds the house. |
| Activities | Data engineers work on tasks like data ingestion, data cleaning, data transformation, data integration, creating and optimizing databases, setting up ETL processes, and managing big data frameworks like Hadoop and Spark. | Data modelers use various techniques to create data models, such as Entity-Relationship Diagrams (ERDs) or Unified Modeling Language (UML) diagrams. |
| Goal | The primary goal of data engineering is to provide a robust and scalable infrastructure for data processing and analysis. | The primary goal of data modeling is to create a clear and consistent representation of data that aids in understanding the relationships and interactions between different data elements. |
Both data engineering and data modeling are essential components of a successful data management strategy and work together to ensure that data is effectively captured, stored, and utilized within an organisation.
Here is how it works:
Throughout the data engineering process, it is important to ensure that the data is of high quality and is stored securely. This may involve implementing data quality standards and monitoring the data to ensure that it meets these standards.
Data engineering plays a crucial role in enabling businesses to unlock the full potential of their data. Here are some of the key benefits of data engineering:
Improved Data Quality: One of the main benefits of data engineering is improved data quality. By designing and implementing effective data engineering processes, businesses can ensure that their data is accurate, consistent, and reliable. This is crucial for making informed decisions and gaining insights from data analysis.
Increased efficiency: Data engineering can also help businesses increase efficiency in their data processing and analysis. By streamlining data collection, storage, and analysis processes, businesses can reduce the amount of time and resources required to manage their data. This can lead to cost savings and increased productivity.
Better Decision Making: With accurate and reliable data, businesses can make better-informed decisions. Data engineering can help businesses collect, store, and analyse data in a way that is optimized for decision-making. By using data analysis tools and techniques, businesses can gain insights into customer behaviour, market trends, and other key factors that impact their business.
Competitive Advantage: By leveraging the power of data engineering, businesses can gain a competitive advantage in their industry. With access to accurate and reliable data, businesses can make better-informed decisions and develop more effective strategies. This can help them stay ahead of the competition and identify new opportunities for growth.
Structured, semi-structured, and unstructured data are classifications used to describe the organisation and format of data. These terms are commonly used in the context of data management and analysis. In general, the data that we collect and store falls into these 3 categories:
Structured: Structured data refers to data that has a well-defined, fixed format. It is organized into rows and columns, similar to a table in a relational database. Each column represents a specific attribute or field, and each row contains a single record with values corresponding to each attribute. Examples of structured data include data in relational databases, spreadsheets, and CSV (Comma Separated Values) files. Structured data is highly organized and can be easily queried and analyzed using traditional database management systems.
Semi-Structured: Semi-structured data is a type of data that does not have a fixed, rigid structure like structured data but does have some organizational elements. It may contain tags, attributes, or hierarchical relationships, making it more flexible and accommodating than structured data. Semi-structured data is typically represented in formats like JSON (JavaScript Object Notation), XML (Extensible Markup Language), or NoSQL databases. The presence of these additional elements allows for more diverse and complex data representations, making it suitable for handling data with varying schemas and evolving structures.
Unstructured: Unstructured data refers to data that lacks a predefined structure or organisation. It does not fit into the traditional row-column format of structured data and does not have a consistent schema. Unstructured data is typically found in the form of text-heavy documents, images, audio files, videos, social media posts, emails, etc. Because of its lack of structure, extracting meaningful information from unstructured data can be challenging. Techniques like natural language processing (NLP) and image recognition are often employed to analyze and derive insights from unstructured data.
In summary, the classification of data into structured, semi-structured, and unstructured categories helps data professionals understand the format and complexity of the data they are working with, which, in turn, determines the appropriate methods and tools for processing, storing, and analyzing that data.
Insights & Resources
In the dynamic realm of data utilization, data engineering stands as the cornerstone for transforming raw information into strategic assets.
Data Integration is much more than just data synchronisation. It's a process of combining data from multiple sources into one central location.

In today’s data-driven world, organisations rely on accurate and timely workforce information to make informed decisions.
At DATA LEAGUE, our expert data engineering consulting services are designed to help businesses at every stage of their data transformation journey. Contact us today to learn more about how we can help you unlock the full potential of your data.
